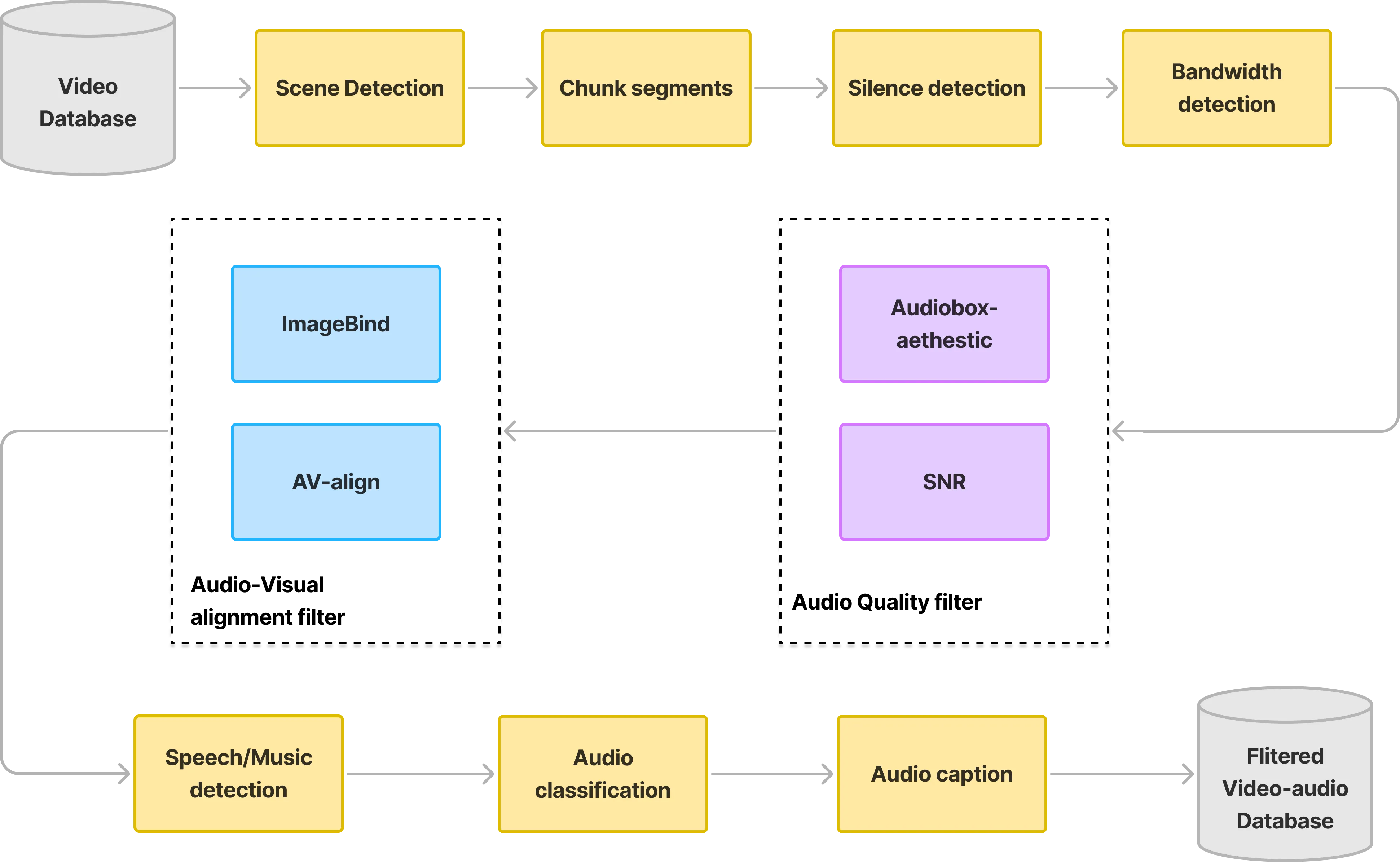
Recent advances in video generation produce visually realistic content, yet the absence of synchronized audio severely compromises immersion. To address key challenges in Video-to-Audio (V2A) generation, including multimodal data scarcity, modality imbalance and limited audio quality in existing V2A methods, we propose HunyuanVideo-Foley, an end-to-end Text-Video-to-Audio (TV2A) framework that synthesizes high-fidelity audio precisely aligned with visual dynamics and semantic context. Our approach incorporates three core innovations: (1) a scalable data pipeline curating 100k-hour multimodal datasets via automated annotation; (2) a novel multimodal diffusion transformer resolving modal competition through dual-stream temporal fusion and cross-modal semantic injection; (3) representation alignment (REPA) using self-supervised audio features to guide latent diffusion training, efficiently improving generation stability and audio quality. Comprehensive evaluations demonstrate that HunyuanVideo-Foley achieves new state-of-the-art performance across audio fidelity, visual alignment and distribution matching.
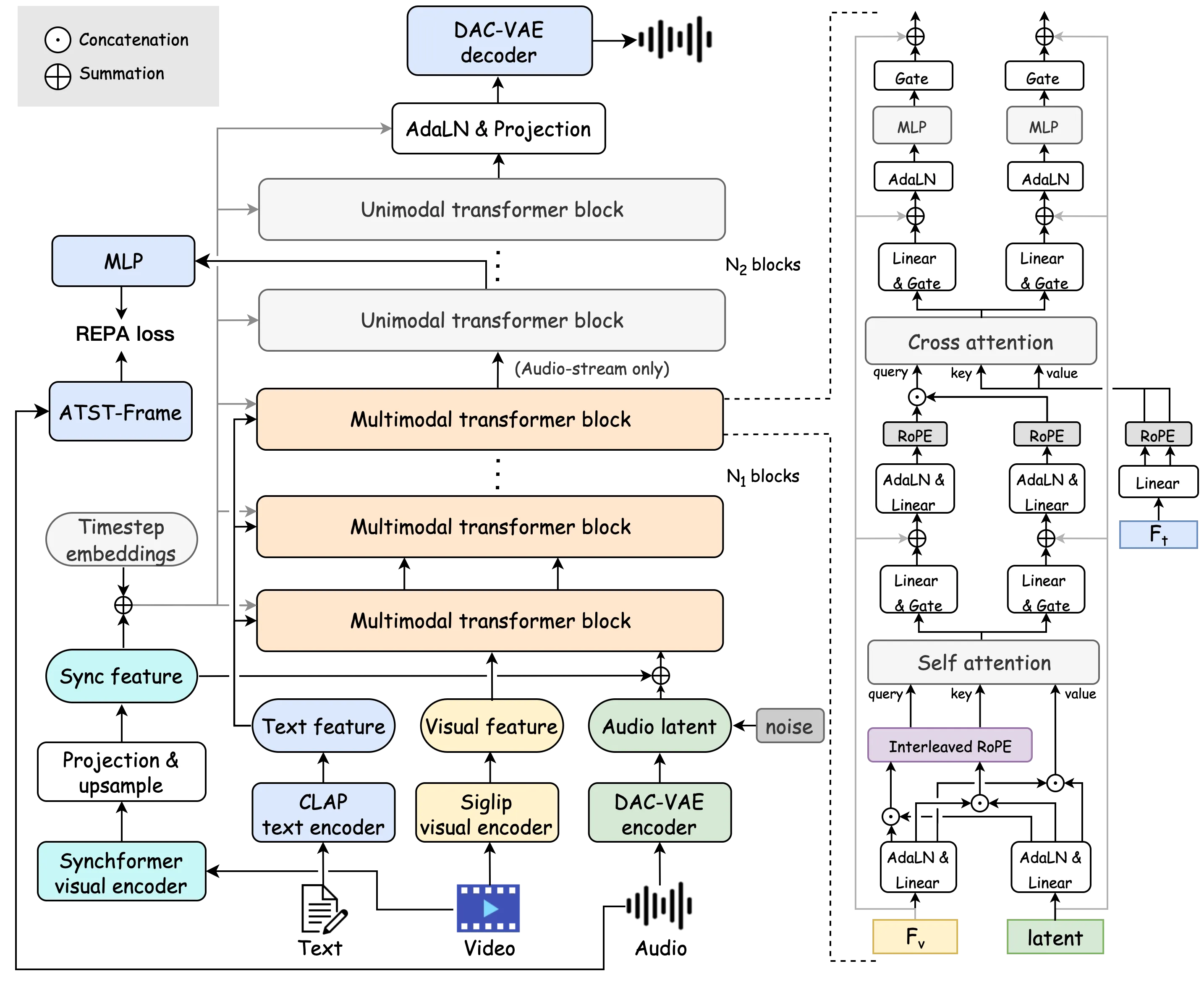
Overview of the HunyuanVideo-Foley model architecture. The proposed model integrates encoded text (CLAP), visual (SigLIP-2), and audio (DAC-VAE) inputs through a hybrid framework with multimodal transformer blocks followed by unimodal transformer blocks. The hybrid transformer blocks are modulated and gated with synchronization features and timestep embeddings. A pre-trained ATST-Frame is used to compute REPA loss with latnet representations from a unimodal transformer block. The generated audio latent are decoded into audio waveforms by the DAC-VAE decoder.
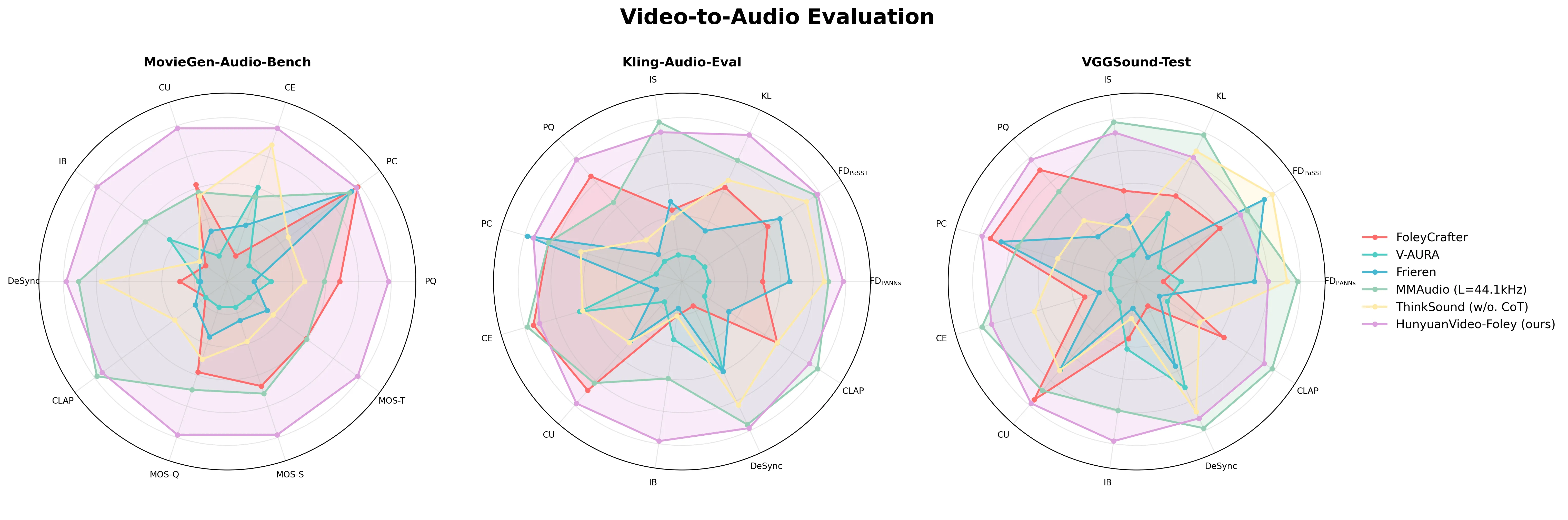
| Method | FDPaNNs↓ | FDPaSST↓ | KL↓ | IS↑ | PQ↑ | PC↓ | CE↑ | CU↑ | IB↑ | DeSync↓ | CLAP↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FoleyCrafter | 22.30 | 322.63 | 2.47 | 7.08 | 6.05 | 2.91 | 3.28 | 5.44 | 0.22 | 1.23 | 0.22 |
| V-AURA | 33.15 | 474.56 | 3.24 | 5.80 | 5.69 | 3.98 | 3.13 | 4.83 | 0.25 | 0.86 | 0.13 |
| Frieren | 16.86 | 293.57 | 2.95 | 7.32 | 5.72 | 2.55 | 2.88 | 5.10 | 0.21 | 0.86 | 0.16 |
| MMAudio | 9.01 | 205.85 | 2.17 | 9.59 | 5.94 | 2.91 | 3.30 | 5.39 | 0.30 | 0.56 | 0.27 |
| ThinkSound | 9.92 | 228.68 | 2.39 | 6.86 | 5.78 | 3.23 | 3.12 | 5.11 | 0.22 | 0.67 | 0.22 |
| HunyuanVideo-Foley (ours) | 6.07 | 202.12 | 1.89 | 8.30 | 6.12 | 2.76 | 3.22 | 5.53 | 0.38 | 0.54 | 0.24 |
| Method | FDPaNNs↓ | FDPaSST↓ | KL↓ | IS↑ | PQ↑ | PC↓ | CE↑ | CU↑ | IB↑ | DeSync↓ | CLAP↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FoleyCrafter | 20.65 | 171.43 | 2.26 | 14.58 | 6.33 | 2.87 | 3.60 | 5.74 | 0.26 | 1.22 | 0.19 |
| V-AURA | 18.91 | 291.72 | 2.40 | 8.58 | 5.70 | 4.19 | 3.49 | 4.87 | 0.27 | 0.72 | 0.12 |
| Frieren | 11.69 | 83.17 | 2.75 | 12.23 | 5.87 | 2.99 | 3.54 | 5.32 | 0.23 | 0.85 | 0.11 |
| MMAudio | 7.42 | 116.92 | 1.77 | 21.00 | 6.18 | 3.17 | 4.03 | 5.61 | 0.33 | 0.47 | 0.25 |
| ThinkSound | 8.46 | 67.18 | 1.90 | 11.11 | 5.98 | 3.61 | 3.81 | 5.33 | 0.24 | 0.57 | 0.16 |
| HunyuanVideo-Foley (ours) | 11.34 | 145.22 | 2.14 | 16.14 | 6.40 | 2.78 | 3.99 | 5.79 | 0.36 | 0.53 | 0.24 |
| Method | PQ↑ | PC↓ | CE↑ | CU↑ | IB↑ | DeSync↓ | CLAP↑ | MOS-Q↑ | MOS-S↑ | MOS-T↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| FoleyCrafter | 6.27 | 2.72 | 3.34 | 5.68 | 0.17 | 1.29 | 0.14 | 3.36±0.78 | 3.54±0.88 | 3.46±0.95 |
| V-AURA | 5.82 | 4.30 | 3.63 | 5.11 | 0.23 | 1.38 | 0.14 | 2.55±0.97 | 2.60±1.20 | 2.70±1.37 |
| Frieren | 5.71 | 2.81 | 3.47 | 5.31 | 0.18 | 1.39 | 0.16 | 2.92±0.95 | 2.76±1.20 | 2.94±1.26 |
| MMAudio | 6.17 | 2.84 | 3.59 | 5.62 | 0.27 | 0.80 | 0.35 | 3.58±0.84 | 3.63±1.00 | 3.47±1.03 |
| ThinkSound | 6.04 | 3.73 | 3.81 | 5.59 | 0.18 | 0.91 | 0.20 | 3.20±0.97 | 3.01±1.04 | 3.02±1.08 |
| HunyuanVideo-Foley (ours) | 6.59 | 2.74 | 3.88 | 6.13 | 0.35 | 0.74 | 0.33 | 4.14±0.68 | 4.12±0.77 | 4.15±0.75 |
Our experimental results demonstrate that HunyuanVideo-Foley achieves superior performance across multiple evaluation datasets, consistently outperforming baseline methods in key metrics related to audio quality, temporal alignment, and cross-modal consistency.
Our HunyuanVideo-Foley framework demonstrates superior performance compared to existing methods. Below are video-audio generation comparisons across different methods:
We provide an extensive comparison of our HunyuanVideo-Foley model against five state-of-the-art methods across 28 different video samples. Each comparison includes the original prompt used for generation, allowing for detailed analysis of how different models interpret and synthesize audio for the same visual content.
Prompt: gentle licking the fur, high-quality
Prompt: dog's tongue lapping against the bowl.
Prompt: gritting teeth and heavy breaths are heard in the deserted alley, as a person walks.
Prompt: thunderous footsteps shake the ground, and the dinosaur's massive roar echoes through the valley.
@misc{shan2025hunyuanvideofoleymultimodaldiffusionrepresentation,
title={HunyuanVideo-Foley: Multimodal Diffusion with Representation Alignment for High-Fidelity Foley Audio Generation},
author={Sizhe Shan and Qiulin Li and Yutao Cui and Miles Yang and Yuehai Wang and Qun Yang and Jin Zhou and Zhao Zhong},
year={2025},
eprint={2508.16930},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2508.16930},
}